
Hadoop Distributed File System
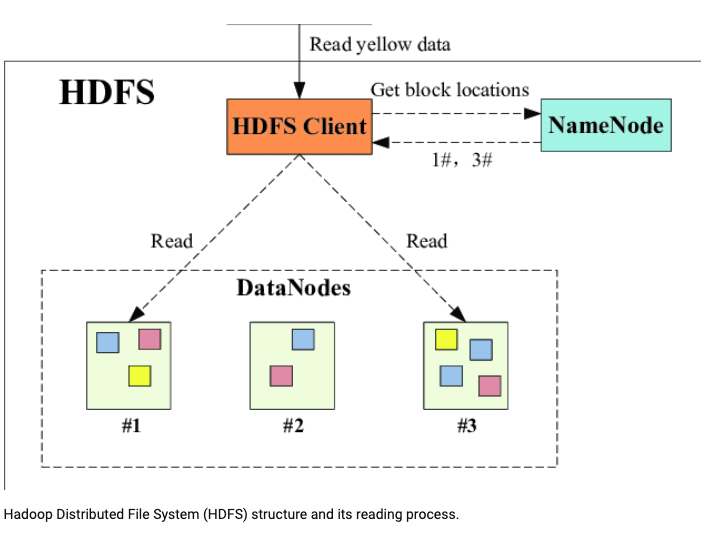
Hadoop Distributed File System (HDFS) is responsible for storing data. It is a distributed file system where data is split into blocks that are stored in multiple locations. It is extremely fault tolerant and works on any type of commodity hardware, making it easily deployable. There are two daemons named Namenode and Datanode. Daemons are processes that run in Hadoop.
-- Namenode: Also called the master daemon. It keeps a log of file locations, permissions, blocks of files etc. This metadata is stored in the form of fsimage and log files. In case of namenode failure, the fsimage is backed up in a secondary namenode so that it can take over. The metadata is updated regularly. Namenode manages the data nodes. Its operations involve managing opening, renaming and closing files.
-- Datanode: Also called the slave daemon. It is responsible for sending heartbeat signals to the namenode every 3 seconds. To protect against failure of a datanode, the data is replicated many times, the default being 3 times. Datanode handles read, write, creation and deletion requests from the client.
The datanode and masternode are pieces of software that typically runs on Linux OS. The Hadoop framework is written in JAVA and can be run in any machine that supports JAVA. The client can request to store, read, write, delete, copy files. The namenode handles these requests and checks for the permissions available to the client. Namenode can then provide access to datanodes for the client to perform file operations. Any file that is submitted to the HDFS, is split into blocks of 128 MB (default) called hdfs blocks.
Picture Source: researchgate.net